Prompt Cache について理解を深める
ふと MLSys の Proceedings を眺めていたら,Prompt Cache の論文(Prompt Cache: Modular Attention Reuse for Low-Latency Inference)を見つけたので,仕組みを知りたくて読んでみました.今回はそれの備忘録になります.この論文での Prompt Cache の機構は,LLM プロバイダーが提供する Prompt caching の仕組みとはドキュメントを見たところ違うものでした.こちらは実用性を重視した機能で,Cache Hits によるプロンプト内でのプレフィックスの一致でキャッシュする方法になります.
論文で提案された Prompt Cache の仕組みを見ていく
特定のタスクを LLM に解かせる際にプロンプトをチューニングしますが,システムプロンプトや指示などの前提となるコンテキストはリクエスト毎に変わらずに使用されることが多いと思います.また,プロンプトはプロンプトエンジニアリングによって再利用可能な形でテンプレート化されることも多く,プロンプト間で重複する部分も多いです.このような背景から,Prompt Cache は異なる複数のプロンプト間でアテンション状態(Key-Value pairs)の再利用を可能にすることで,Time-To-First-Token (TTFT) のレイテンシを大幅に削減することを実現する技術です.
既存の計算コスト削減方法である Key-Value Cache との比較
Transformer では,各トークンを生成する際に全ての過去のトークンとのアテンション状態を再計算する必要がありますが,これは非常に計算コストがかかり非効率です.KV Cache では,入力に対して最初にアテンション状態を一度計算することで,以降はそれを再利用します(過去に生成されたトークンのキーとバリューを保存しておいて,新しいトークンを生成する際にこれらを再利用する).これは prefill phase と呼ばれます.計算量は現在のシーケンス長を n,隠れ層の次元数を d とすると,過去のトークンとのアテンション計算が O(nd) なので,n 個のトークンを生成する場合,O(n × nd) = O(n²d) となります.1ステップで考えると,過去のキーとバリューをキャッシュしておき,次のステップでは新しいクエリに対してだけ計算すればいいので,O(nd) になります.つまり,1ステップあたりは線形にしか増えません.
ここまでは,KV Cache の話ですが,Prompt Cache はアテンション状態の再利用を単一プロンプトから複数プロンプトへと拡張したものになります.計算結果をメモリ上に保存しておくことで,再計算せずにメモリから取り出して使用します.下図は,Prompt Cache がプロンプトアテンションの計算をバイパスすることで,異なるプロンプト間での再利用を実現する仕組みを表現しています.
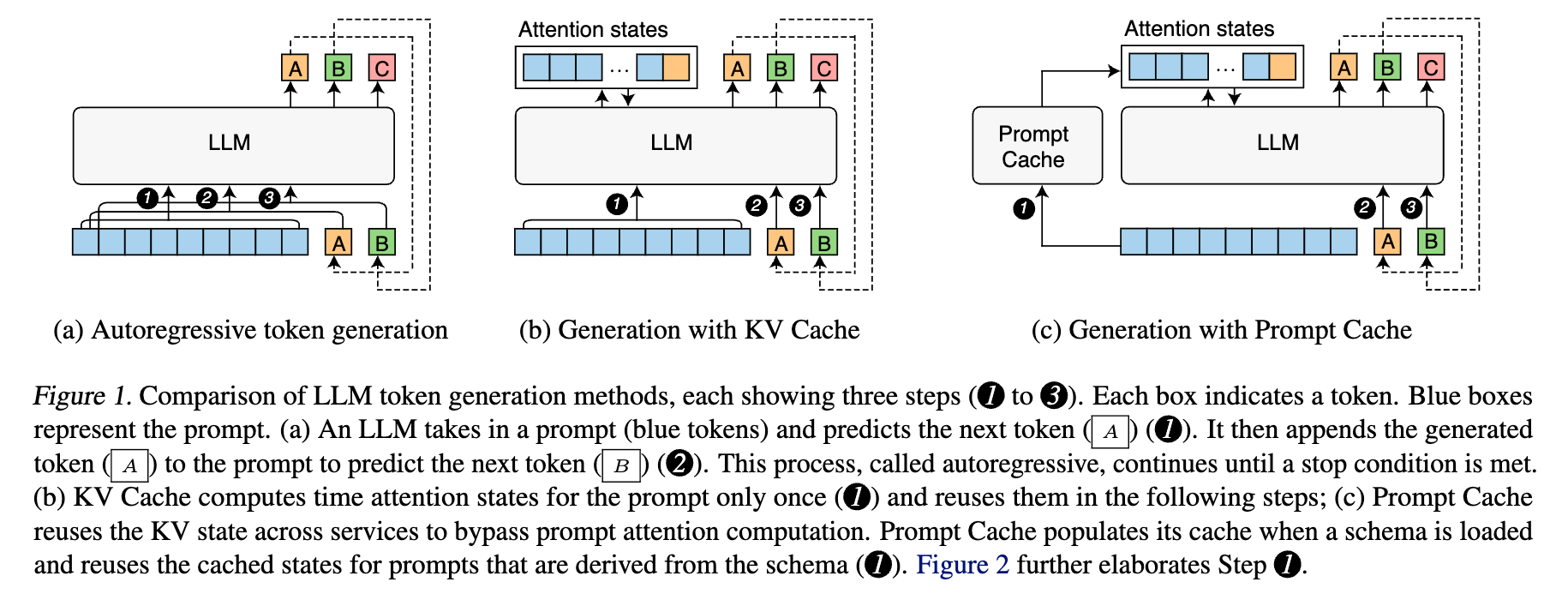
どのようにして複数プロンプト間でアテンション状態を再利用するか?
Transformer のアテンション状態は位置エンコーディングによって位置依存性を持ちます.KV Cache を用いて単一のプロンプトを扱う場合は,同じプロンプトコンテキストがすべてのステップにおいて同じ位置に配置されることから問題になりません.一方で,複数のプロンプト間で共有されるテキストセグメント(テキストの集合/塊)はプロンプト間で異なる位置・状態に現れる可能性があるため,以下の2つの問題に対応する必要性を挙げています.
- テキストセグメントが異なるプロンプトにおいて異なる位置に現れる場合でも再利用可能にする
- 新しいプロンプトを受け取った際に,アテンション状態がキャッシュされている可能性のあるテキストセグメントを効率的に認識する
これらの問題を解決するために,この論文では2つのアイデアを組み合わせた提案をしています.
- Prompt Markup Language (PML) の導入によるプロンプトの構造を明示的に記述する
- LLM が不連続な位置 ID を持つアテンション状態を処理する(経験則的に可能である)
PML は再利用可能なテキストセグメントをスキーマに落とし込みます.ここでのスキーマは,プロンプトモジュールを定義することと,それらの相対位置と階層を記述します.これにより各プロンプトモジュールに固有の位置 ID が割り当てられます.
各スキーマは一意の識別子を持ち,プロンプトモジュールは <module> タグで指定し,プロンプトは <prompt> タグを使用してスキーマから構築されます.このタグは,schema 属性で利用するスキーマを指定して,インポートするプロンプトモジュールを用意します.
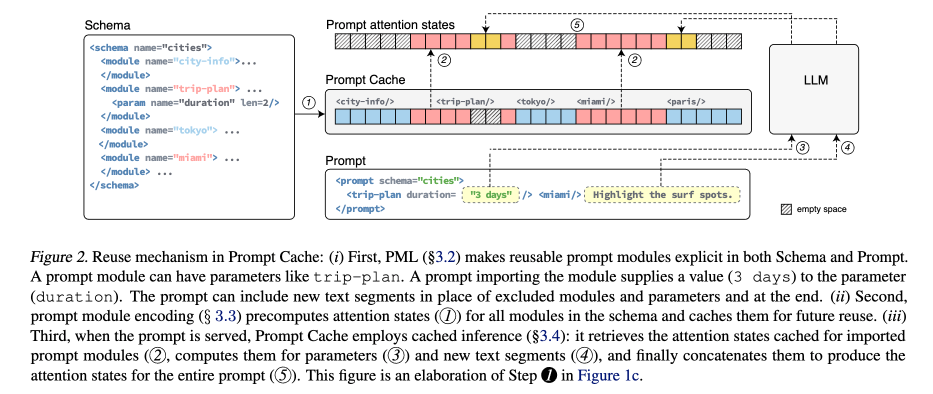
例えば,論文図2のスキーマから miami モジュールをインポートするには,<miami/> と記述します.Prompt Cache は,スキーマで指定されていないテキスト(例: 図2の "Highlight the surf spots")のアテンション状態のみを計算して,インポートされたモジュール(例: trip-plan, miami)のアテンション状態を再利用することでレイテンシを削減しています.他に PML では,プロンプトモジュールのパラメータ化を可能にすることで,再利用性を高めています.
プロンプトモジュールのアテンション状態が必要になったタイミングで,それらは計算されてメモリに保存されます(スキーマのエンコーディング).手続きとしては,Prompt Cache はスキーマからプロンプトモジュールのトークン系列を抽出して,各トークンに位置 ID を割り当てます.プロンプトモジュールのトークン系列と対応する位置 ID は,その後 LLM に渡されて,アテンション状態が計算されます.パラメータに関しては,所定数の <unk> トークン(未知のトークン)で置き換えられます.
推論プロセス
論文図2に示されているように,Prompt Cache は以下のステップを実行します.
- キャッシュからのアテンション状態の取得: インポートされたプロンプトモジュールの事前計算済みアテンション状態をキャッシュから取得する(ステップ2)
- 新しいテキストの計算: キャッシュされていない新しいテキストセグメント(ステップ3と4)のアテンション状態を計算する
- アテンション状態の連結: 1, 2 に加えて,計算済みのパラメータのアテンション状態を連結して,プロンプト全体のアテンション状態を生成する(ステップ5)
これにより,従来の prefill phase が置き換えられます.大部分のアテンション状態は事前計算済みで,新しく計算が必要なのはパラメータ値と新しいテキストのみになります.この仕組みによって,同じスキーマから派生した他のプロンプトでも同じキャッシュを再利用可能にしたり,長いプロンプトでも大部分の計算を省略できて,高速化が実現されるようになります.
Prompt Cache の性能と評価結果
論文では,以下の評価観点が挙げられています.
- Prompt Cache が最初のトークン生成までの時間(TTFT)のレイテンシと出力品質に与える影響
- メモリストレージのオーバーヘッド
- Prompt Cache が適しているアプリケーション(今回は触れず...)
ベースラインには,通常の KV Cache を使用しています.また,評価のために用意した環境とデータセットは,以下の通りになっています.
- CPU 構成: Intel i9-13900K (128 GB DDR5 RAM), AMD Ryzen 9 7950X (128 GB DDR4 RAM)
- GPU 構成: NVIDIA RTX 4090 (Intel i9-13900K とペア), NVIDIA A40、NVIDIA A100 (NCSA Delta 上の仮想ノード)
- LLM: Llama2, CodeLlama, MPT, Falcon などの OSS LLM を使用
- データセット: LongBench (4K から 10K のコンテキスト長を持つ,6つのカテゴリ(多文書質疑応答・要約・コード補完など)にわたる21のデータセットからの厳選されたサンプル)
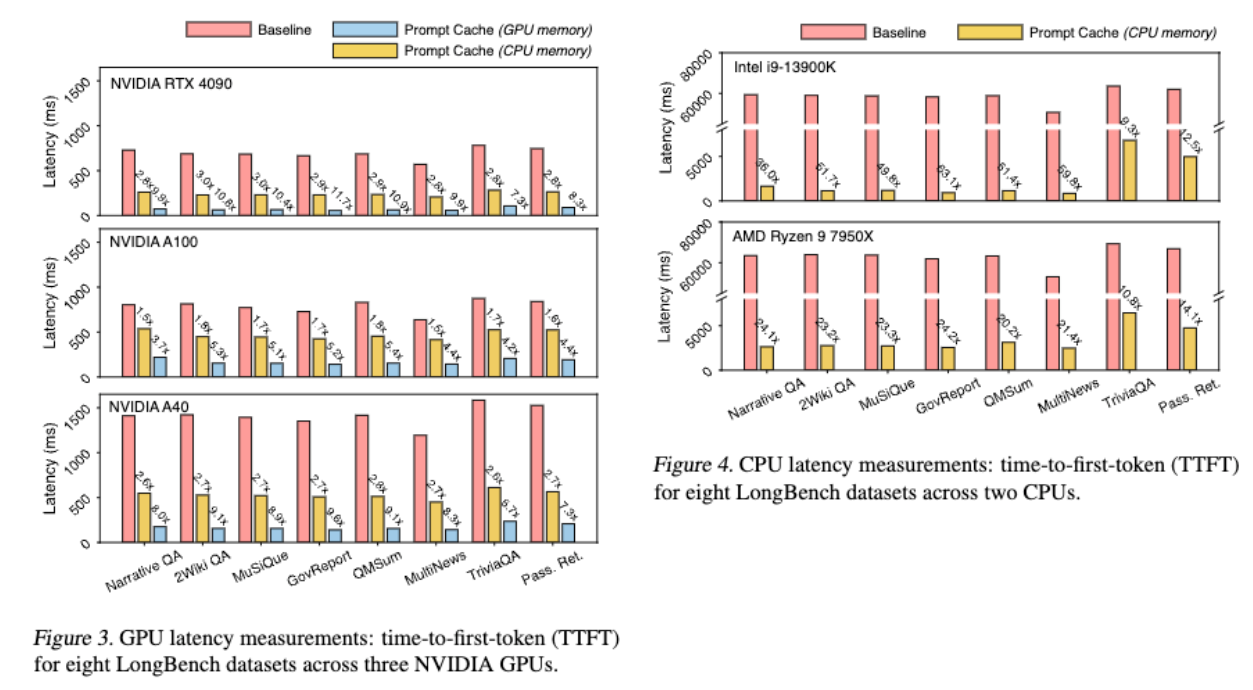
図3では,プロンプトモジュールを CPU メモリに保存した場合,TTFT レイテンシは1.5~3倍に削減され,GPU メモリに保存した場合は,5倍~10倍に削減されています.図4では,Intel CPU で最大70倍,AMD CPU では最大20倍のレイテンシ削減を実現しています.CPU でのアテンション計算のレイテンシーが GPU よりはるかに大きいため,CPU 推論は GPU 推論よりも Prompt Cache からより大きな恩恵を受けています.
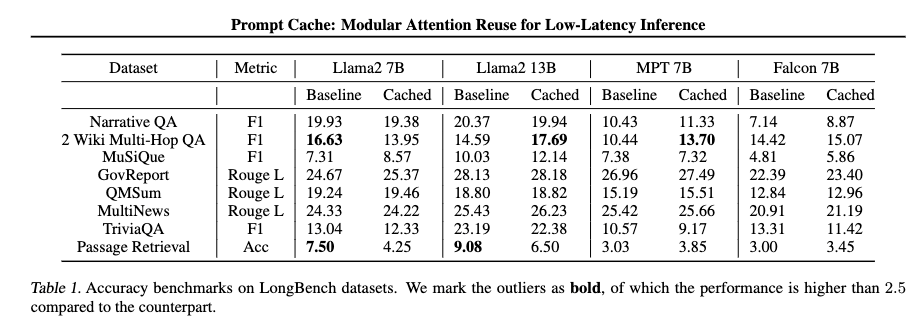
表1を見ると,精度面においても Prompt Cache による出力はベースラインと比較して同等の精度維持していることがわかります.
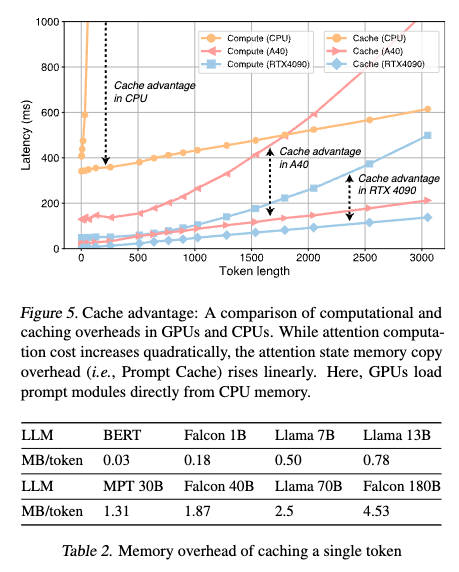
論文では,レイテンシー改善をどう理解するかが述べられています.KV Cache のレイテンシーがシーケンス長とともに二次的に増加する(セルフアテンションの計算)のに対して,Prompt Cache のメモリコピーのコストは線形に増加することが示されています.モデルサイズの影響に関しても,モデルのパラメータサイズが大きくなるにつれて,KV Cache の計算オーバーヘッドも増加します.例えば,7B モデルから13B モデルにし,3K トークン長を与えた場合,KV Cache では220ms のレイテンシーが追加されるのに対して,Prompt Cache では30ms しか追加されていません.
Prompt Cache を行うためには,メモリ上に留めておく必要があるわけですが,表2の値を参考にすると,メモリとしては CPU しか現状は難しそうですね.
| 1K tokens の docs をキャッシュする場合 | モデル | メモリ使用量 |
|---|---|---|
| Llama 7B | 500MB | |
| Llama 70B | 2.5GB |
| 100docs (1K tokens) キャッシュする場合 | モデル | メモリ使用量 |
|---|---|---|
| Llama 7B | 50GB | |
| Llama 70B | 250GB |
というわけで,Prompt Cache に関する論文を紹介しましたが,複数のプロンプト間でアテンション状態をキャッシュして再利用するという非常に興味深い技術だなと思いました.LLM を活用したレイテンシーに敏感なアプリケーション,リアルタイム応答だったりの推論を考えた場合に,こういった仕組みは必要になってくるだろうなと思います.PML を構築する部分は少々厄介かなと思いつつ,この辺のキャッシュ機構については面白いトピックだと思うので,他の論文とかも眺めたいなと思いました.
後半は LLM サービスプロバイダーでの実用的なキャッシュの仕組みを紹介します.
LLM サービスプロバイダーでの Prompt caching の仕組み
OpenAI と Anthropic で提供されている仕組みについてメインで紹介します.他に,Google (Gemini) や Microsoft がありますが,基本的な仕組みは他のサービスプロバイダーと同じです.Implicit caching な仕組みと Explicit caching な仕組みがあり,Explicit の方は Time to Live (TTL) が設定できたりでトークンサイズに合わせてコストがかかる仕様になっています.
OpenAI の Prompt caching の仕組み
OpenAI では,Cache Hit という仕組みによってシステムにデータをキャッシュしておくことで,レイテンシーやコストが削減される機能があり,それが Prompt caching になります.この機能はコード変更不要で自動的に有効になります.
下図は OpenAI のガイドから拝借していますが,この図の通りでプロンプト内でプレフィックスが完全に一致する場合にのみ Cache Hit が効く仕組みです.

このガイドではもう少し詳しくどのように動作するか説明があります.
- Cache Routing
- リクエストされると,プロンプトのプレフィックスのハッシュ値(最初の 256 トークンが使用される)に基づいてルーティングされる.
- Cache Lookup
- ルーティングされた結果が,キャッシュに存在するかどうかを確認する.
- Cache Hit
- 一致するプレフィックスが見つかった場合は,システムはキャッシュされた結果を利用する.
- Cache Miss
- 一致するプレフィックスが見つからない場合は,システムはプロンプト全体を処理した後,そのプレフィックスをキャッシュして,将来のリクエストに備える.
キャッシュは1024トークン以上のプロンプトで利用可能で,これ以下の場合は機能しない仕様となっているそうです.また,追加で128トークンずつキャッシュヒットが発生する仕組みです.キャッシュ対象は,Messages, Images, Tool use, Structured outputs になります.
あとはプラクティスとして,キャッシュのメリットを効果的に享受するためには,システムプロンプトや指示,例などの静的コンテンツをプロンプトの前半に配置して,リクエストによって可変になる情報はプロンプトの後半に配置するというのが書かれていました.
Anthropic (Claude) の Prompt caching の仕組み
Claude の Prompt caching の仕組みは,Explicit caching な仕組みで,cache_control パラメータを使用してキャッシュしたい部分を指定する必要があります.
この設定を有効にしてリクエストを送ると,
- システムは指定されたキャッシュブレイクポイントまでのプレフィックス一致が,直近のクエリから既にキャッシュされているかを確認する
- キャッシュされている場合は,キャッシュされたバージョンを使用する
- キャッシュされていない場合は,プロンプト全体を処理して,レスポンスが開始されるとプレフィックスをキャッシュする
デフォルトでは,キャッシュの TTL は5分間になっています.対応するモデルやコストは公式ドキュメントを確認して下さい.
下記のサンプルコード(公式ドキュメントにある)では,ユーザーインストラクション部分はキャッシュせず,ロングコンテキストであるシステムプロンプトの50ページほどある法的契約の全文をプレフィックスとしてキャッシュしています."cache_control": {"type": "ephemeral"} のパラメータがキャッシュの設定を明示的に行う部分になっています.
import anthropic
client = anthropic.Anthropic()
response = client.messages.create(
model="claude-opus-4-20250514",
max_tokens=1024,
system=[
{
"type": "text",
"text": "You are an AI assistant tasked with analyzing legal documents."
},
{
"type": "text",
"text": "Here is the full text of a complex legal agreement: [Insert full text of a 50-page legal agreement here]",
"cache_control": {"type": "ephemeral"} # キャッシュの設定を明示的に行う
}
],
messages=[
{
"role": "user",
"content": "What are the key terms and conditions in this agreement?"
}
]
)
print(response.model_dump_json())キャッシュ対象は,Tools, System messages, Text messages, Images / Documents, Tool use と tool results になります.一方でキャッシュ対象外も定義されていて,Thinking blocks, 引用などのサブコンテンツブロック, 空のテキストブロック が対象外になっています.
プラクティスとして,OpenAI との違いを見ると,Claude では最大4つのキャッシュブレイクポイントを定義できるため,異なる再利用可能なセクションを独立してキャッシュすることができます.これを有効に利用することを勧めています.
他には,TTL が1時間のキャッシュも用意されているので,5分のキャッシュと組み合わせた Mixing different TTLs によるより効果的に最適化する例も紹介されています.
今回は Prompt Cache の論文と LLM サービスプロバイダーでの Prompt caching の仕組みについて少し調べてみたので,整理してみました.他にも関連するトピックの論文がいくつかあるので,また読んだら整理していきたいと思います.